 |
DarkMark
v1.11.11-1
Image markup for darknet machine learning.
|


|
|
DarkMark
v1.11.11-1
Image markup for darknet machine learning.
|
|
There are 3 things to consider when talking about the size of objects to detect:
416x416 or 608x608. [FAQ] 1920x1080. Darknet only cares about the network dimensions, and has no concept of the other two. (While people looking at images typically ignore the network dimensions and only notice the other two!)
When an image is given to Darknet – either for training or for inference – the first thing it does is convert the image to exactly match the network dimensions. So even if you have extremely high definition images at 8000x6000, the first thing Darknet will do before looking at it is resize the entire thing to 416x416. (Or whatever network dimensions you are using.)
If the objects you'd like to find in your images are big, and you resize the image to 416x416, the object will still be relatively big, and image recognition happens normally. If this is the case and everything is working correctly, you can stop reading here.
But if your objects within your high resolution images are small, once the images are resized and stretched to match the network dimensions, the objects become so tiny they're virtually impossible to detect.
This is where image tiling can help. The inference side of image tiling is described on the DarkHelp web page.
Meanwhile, from a DarkMark perspective there are 3 options related to image size and tiling. These are in the Darknet window, where you can choose to leave images as-is, resize images, or tile images:
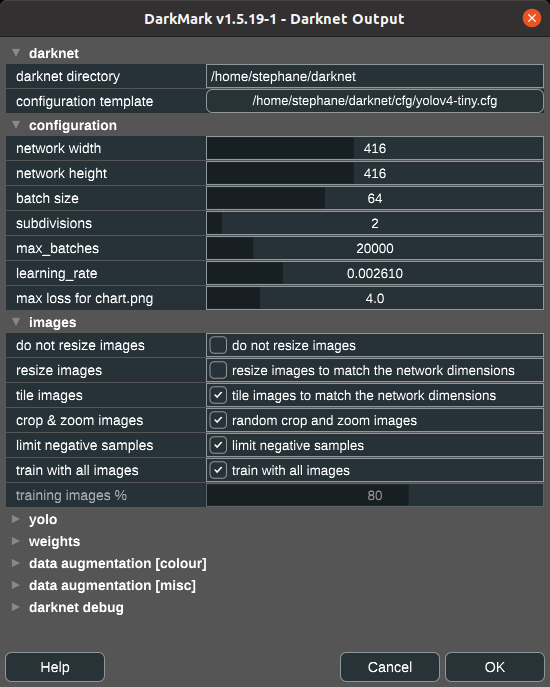
More details on this can also be found in the Youtube video linked above. The section where this is discussed further begins at 4m38s.
 1.8.17
1.8.17