 |
DarkMark
v1.11.11-1
Image markup for darknet machine learning.
|


|
|
DarkMark
v1.11.11-1
Image markup for darknet machine learning.
|
|
Being consistent is very important when marking up images. When possible, you'll want to make certain that all instances of a particular class are all marked the same way.
For example, Note how all sides of the speed limit sign are marked up in these images:

| 
| 
|
When possible, such as these street signs with straight edges, you only mark exactly what is needed – no more, no less.
If the object is not "square", or viewed from an angle, then make sure the markup includes all parts of the object visible in the image. Again, no more, and no less.
Click and drag on the corners of the marks to grow or shrink the selection as necessary until the all of the visible parts are fully within the mark selection.

| 
| 
|
The way to deal with partially obscured objects depends on how much of the object is available, and how you want the neural network to learn.

If we take the right-hand-side bicycle in this example, note there is a post in front of it. Yet, when marking up this image, I definitely wouldn't mark this as two different bicycles, one on each side of the post. (I'm ignoring the fact this is a tandem bike!) This way, the neural network learns that sometimes part of an object may be obscured.
The front wheel sticking out of the bottom left is a more difficult call. Generally, if most of an object is visible, then it should be tagged. Or if a significant portion of an image is identifiable, then it should be tagged. Thing is, a bicycle tire with the standard wheel spokes is pretty identifiable. An argument could be made either way in this example.
But this does bring up something important about obscured objects: only mark up the parts of the image which are visible, not the parts that you "know" should be there but which are obscured!

In this previous example image, even if we know the front wheel extends further to the bottom left, we can only mark what the neural network should expect to find in this exact image. You are training the neural network to see exactly what is available, not what it should logically know. Context is irrelevant with these neural networks, you are only training it to recognize the exact object you can see in the image.
Which brings up our last strange example: the infamous Vashon Island bicycle tree. Should this image end up in my network, I'd mark it as a single item like this:

...but just how many images of bicycles eaten by trees are you expecting to encounter with your neural network?
When multiple instances of an object appears in an image, you must ensure that every single one is properly marked. Otherwise, training will be negatively impacted. If you want your network to recognize cars, and you fail to mark up several cars in an image, then the training will incorrectly think it has learned the wrong thing when it identifies those cars during training/validation.
This first example is the wrong thing to do, while this second image is correct:
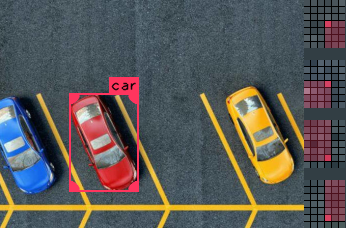
This is a bad example! | 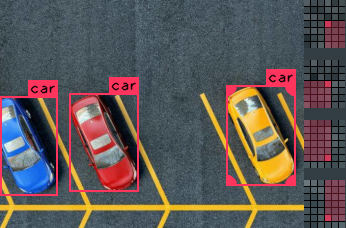
This is a good example. |
"blue car" and "red car", then you'd have different classes for each one, treat them as completely different objects, and you'd tweak the Data Augmentation - Colour settings to not mess with the colour of the training images. But that's a more advanced topic, and if you are just getting started is beyond the scope of this document.And yes, marking every instance of an object in some cases does get very repetitive, but remember that if you mark anything in an image, you must mark all of it. The good news is once you start to train your network, DarkMark will use the .weights file to assist in marking, which makes this process go faster as you can simply accept the predictions (see 'a' in Keyboard Shortcuts) and then edit the ones that need to be tweaked by dragging the corners. The more images you mark up, the "smarter" your neural network will appear to be.

Having overlapping objects is perfectly acceptable. In this example:

You can never have too many images when training a neural network. But, there is a diminishing rate of return after you reach a certain stage. If you have thousands of nearly identical images, by the time you mark your 1000th image, the neural network has probably already learned what the class looks like.
If instead you have 5 big variations and your image set contains 200 images of each one, the neural network trained on those 1000 images will probably be much better than the one from the previous example with 1000 nearly identical images.
The MAP (mean average precision) and the LOSS charts can somewhat help with that during training, letting you know if the neural network training is successful. But if things aren't working as expected, it wont tell you why, which images, or which classes are causing a problem.
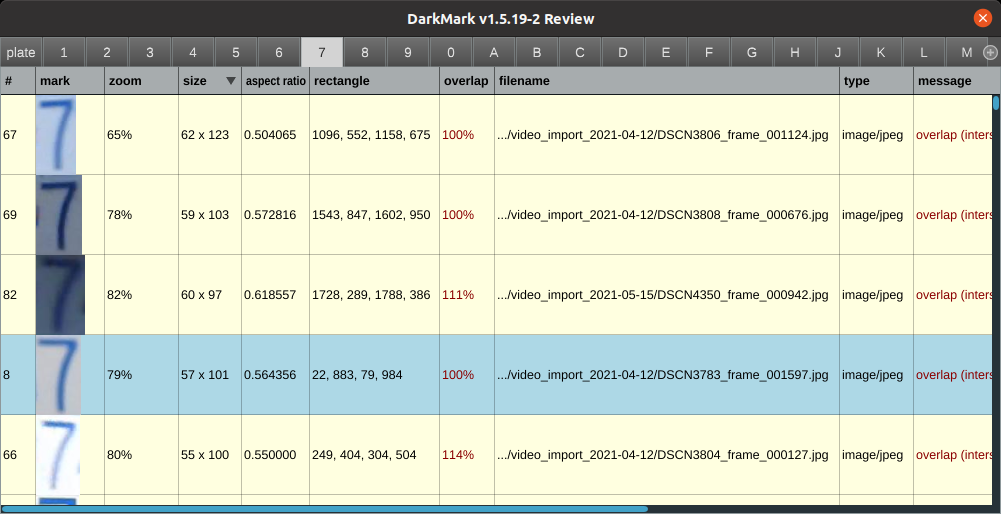
DarkMark has some tools to help you get some insight into the images and markup used to train. For example, the DarkMark Review window will give you an idea of how balanced your classes happen to be. If you have 2000 images of ClassA and only 75 images of ClassB, then don't be surprised if that second class is not working correctly.
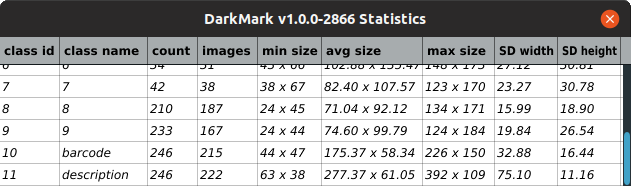
Similarly, the DarkMark Statistics window can provide additional information on the image markup across all images. Pay particular attention to the "min size" and "max size" columns to make sure everything makes sense.
 1.8.17
1.8.17