|
tesseract
v4.0.0-17-g361f3264
Open Source OCR Engine
|


|
|
tesseract
v4.0.0-17-g361f3264
Open Source OCR Engine
|
|
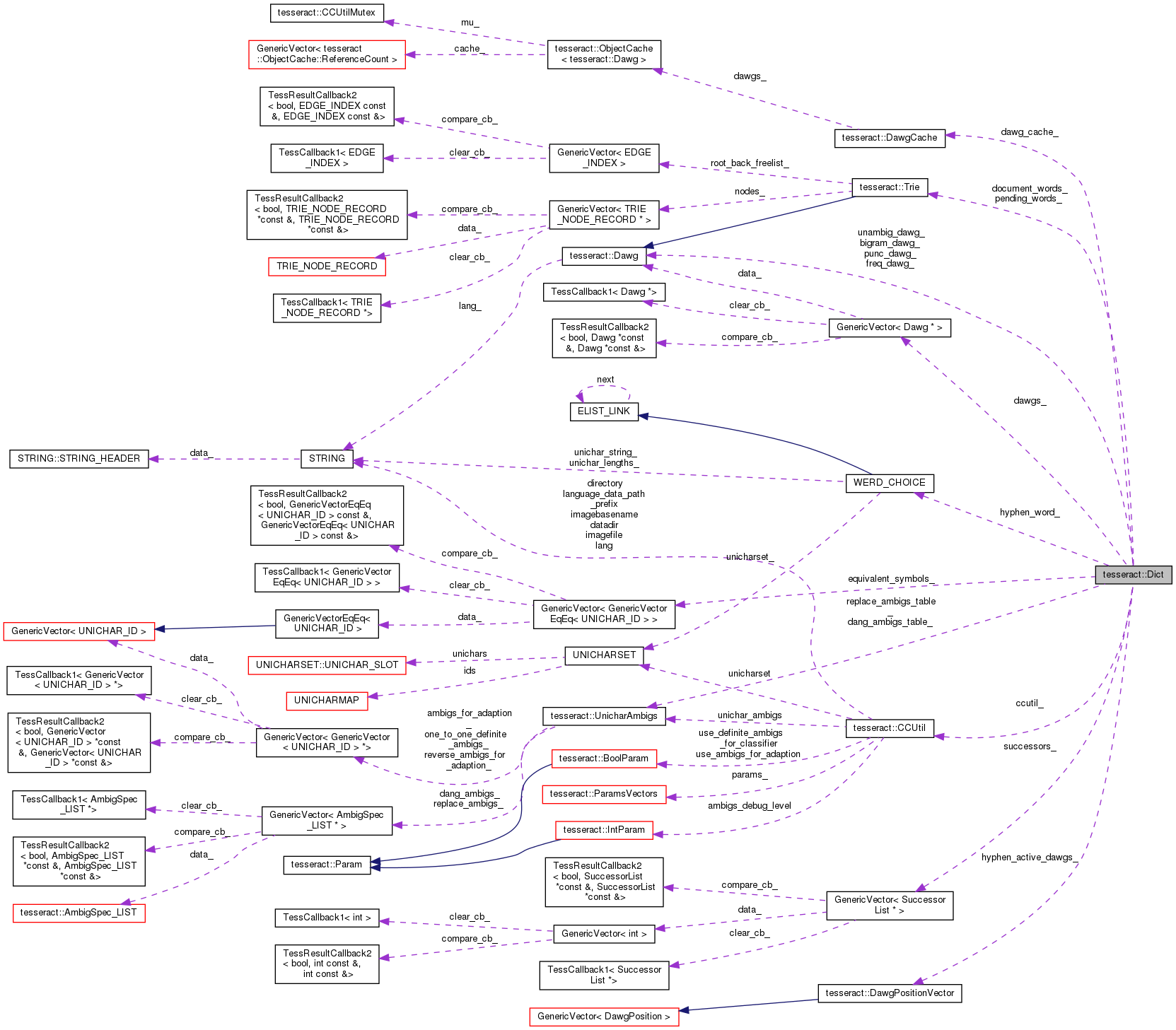
#include <dict.h>
Public Member Functions | |
| Dict (CCUtil *image_ptr) | |
| ~Dict () | |
| const CCUtil * | getCCUtil () const |
| CCUtil * | getCCUtil () |
| const UNICHARSET & | getUnicharset () const |
| UNICHARSET & | getUnicharset () |
| const UnicharAmbigs & | getUnicharAmbigs () const |
| bool | compound_marker (UNICHAR_ID unichar_id) |
| bool | is_apostrophe (UNICHAR_ID unichar_id) |
| bool | hyphenated () const |
| Returns true if we've recorded the beginning of a hyphenated word. More... | |
| int | hyphen_base_size () const |
| Size of the base word (the part on the line before) of a hyphenated word. More... | |
| void | copy_hyphen_info (WERD_CHOICE *word) const |
| bool | has_hyphen_end (UNICHAR_ID unichar_id, bool first_pos) const |
| Check whether the word has a hyphen at the end. More... | |
| bool | has_hyphen_end (const WERD_CHOICE &word) const |
| Same as above, but check the unichar at the end of the word. More... | |
| void | reset_hyphen_vars (bool last_word_on_line) |
| void | set_hyphen_word (const WERD_CHOICE &word, const DawgPositionVector &active_dawgs) |
| void | update_best_choice (const WERD_CHOICE &word, WERD_CHOICE *best_choice) |
| void | init_active_dawgs (DawgPositionVector *active_dawgs, bool ambigs_mode) const |
| void | default_dawgs (DawgPositionVector *anylength_dawgs, bool suppress_patterns) const |
| bool | NoDangerousAmbig (WERD_CHOICE *BestChoice, DANGERR *fixpt, bool fix_replaceable, MATRIX *ratings) |
| void | ReplaceAmbig (int wrong_ngram_begin_index, int wrong_ngram_size, UNICHAR_ID correct_ngram_id, WERD_CHOICE *werd_choice, MATRIX *ratings) |
| int | LengthOfShortestAlphaRun (const WERD_CHOICE &WordChoice) const |
| Returns the length of the shortest alpha run in WordChoice. More... | |
| int | UniformCertainties (const WERD_CHOICE &word) |
| bool | AcceptableChoice (const WERD_CHOICE &best_choice, XHeightConsistencyEnum xheight_consistency) |
| Returns true if the given best_choice is good enough to stop. More... | |
| bool | AcceptableResult (WERD_RES *word) const |
| void | EndDangerousAmbigs () |
| void | DebugWordChoices () |
| Prints the current choices for this word to stdout. More... | |
| void | SettupStopperPass1 () |
| Sets up stopper variables in preparation for the first pass. More... | |
| void | SettupStopperPass2 () |
| Sets up stopper variables in preparation for the second pass. More... | |
| int | case_ok (const WERD_CHOICE &word, const UNICHARSET &unicharset) const |
| Check a string to see if it matches a set of lexical rules. More... | |
| bool | absolute_garbage (const WERD_CHOICE &word, const UNICHARSET &unicharset) |
| void | SetupForLoad (DawgCache *dawg_cache) |
| void | Load (const STRING &lang, TessdataManager *data_file) |
| void | LoadLSTM (const STRING &lang, TessdataManager *data_file) |
| bool | FinishLoad () |
| void | End () |
| void | ResetDocumentDictionary () |
| int | def_letter_is_okay (void *void_dawg_args, const UNICHARSET &unicharset, UNICHAR_ID unichar_id, bool word_end) const |
| int | LetterIsOkay (void *void_dawg_args, const UNICHARSET &unicharset, UNICHAR_ID unichar_id, bool word_end) const |
| Calls letter_is_okay_ member function. More... | |
| double | ProbabilityInContext (const char *context, int context_bytes, const char *character, int character_bytes) |
| Calls probability_in_context_ member function. More... | |
| double | def_probability_in_context (const char *lang, const char *context, int context_bytes, const char *character, int character_bytes) |
| Default (no-op) implementation of probability in context function. More... | |
| double | ngram_probability_in_context (const char *lang, const char *context, int context_bytes, const char *character, int character_bytes) |
| float | ParamsModelClassify (const char *lang, void *path) |
| float | CallParamsModelClassify (void *path) |
| void | SetWildcardID (UNICHAR_ID id) |
| UNICHAR_ID | WildcardID () const |
| int | NumDawgs () const |
| Return the number of dawgs in the dawgs_ vector. More... | |
| const Dawg * | GetDawg (int index) const |
| Return i-th dawg pointer recorded in the dawgs_ vector. More... | |
| const Dawg * | GetPuncDawg () const |
| Return the points to the punctuation dawg. More... | |
| const Dawg * | GetUnambigDawg () const |
| Return the points to the unambiguous words dawg. More... | |
| UNICHAR_ID | char_for_dawg (const UNICHARSET &unicharset, UNICHAR_ID ch, const Dawg *dawg) const |
| void | ProcessPatternEdges (const Dawg *dawg, const DawgPosition &info, UNICHAR_ID unichar_id, bool word_end, DawgArgs *dawg_args, PermuterType *current_permuter) const |
| int | valid_word (const WERD_CHOICE &word, bool numbers_ok) const |
| int | valid_word (const WERD_CHOICE &word) const |
| int | valid_word_or_number (const WERD_CHOICE &word) const |
| int | valid_word (const char *string) const |
| This function is used by api/tesseract_cube_combiner.cpp. More... | |
| bool | valid_bigram (const WERD_CHOICE &word1, const WERD_CHOICE &word2) const |
| bool | valid_punctuation (const WERD_CHOICE &word) |
| int | good_choice (const WERD_CHOICE &choice) |
| Returns true if a good answer is found for the unknown blob rating. More... | |
| void | add_document_word (const WERD_CHOICE &best_choice) |
| Adds a word found on this document to the document specific dictionary. More... | |
| void | adjust_word (WERD_CHOICE *word, bool nonword, XHeightConsistencyEnum xheight_consistency, float additional_adjust, bool modify_rating, bool debug) |
| Adjusts the rating of the given word. More... | |
| void | SetWordsegRatingAdjustFactor (float f) |
| Set wordseg_rating_adjust_factor_ to the given value. More... | |
| bool | IsSpaceDelimitedLang () const |
| Returns true if the language is space-delimited (not CJ, or T). More... | |
| STRING_VAR_H (user_words_file, "", "A filename of user-provided words.") | |
| STRING_VAR_H (user_words_suffix, "", "A suffix of user-provided words located in tessdata.") | |
| STRING_VAR_H (user_patterns_file, "", "A filename of user-provided patterns.") | |
| STRING_VAR_H (user_patterns_suffix, "", "A suffix of user-provided patterns located in tessdata.") | |
| BOOL_VAR_H (load_system_dawg, true, "Load system word dawg.") | |
| BOOL_VAR_H (load_freq_dawg, true, "Load frequent word dawg.") | |
| BOOL_VAR_H (load_unambig_dawg, true, "Load unambiguous word dawg.") | |
| BOOL_VAR_H (load_punc_dawg, true, "Load dawg with punctuation patterns.") | |
| BOOL_VAR_H (load_number_dawg, true, "Load dawg with number patterns.") | |
| BOOL_VAR_H (load_bigram_dawg, true, "Load dawg with special word bigrams.") | |
| double_VAR_H (xheight_penalty_subscripts, 0.125, "Score penalty (0.1 = 10%) added if there are subscripts " "or superscripts in a word, but it is otherwise OK.") | |
| double_VAR_H (xheight_penalty_inconsistent, 0.25, "Score penalty (0.1 = 10%) added if an xheight is " "inconsistent.") | |
| double_VAR_H (segment_penalty_dict_frequent_word, 1.0, "Score multiplier for word matches which have good case and" "are frequent in the given language (lower is better).") | |
| double_VAR_H (segment_penalty_dict_case_ok, 1.1, "Score multiplier for word matches that have good case " "(lower is better).") | |
| double_VAR_H (segment_penalty_dict_case_bad, 1.3125, "Default score multiplier for word matches, which may have " "case issues (lower is better).") | |
| double_VAR_H (segment_penalty_dict_nonword, 1.25, "Score multiplier for glyph fragment segmentations which " "do not match a dictionary word (lower is better).") | |
| double_VAR_H (segment_penalty_garbage, 1.50, "Score multiplier for poorly cased strings that are not in" " the dictionary and generally look like garbage (lower is" " better).") | |
| STRING_VAR_H (output_ambig_words_file, "", "Output file for ambiguities found in the dictionary") | |
| INT_VAR_H (dawg_debug_level, 0, "Set to 1 for general debug info" ", to 2 for more details, to 3 to see all the debug messages") | |
| INT_VAR_H (hyphen_debug_level, 0, "Debug level for hyphenated words.") | |
| INT_VAR_H (max_viterbi_list_size, 10, "Maximum size of viterbi list.") | |
| BOOL_VAR_H (use_only_first_uft8_step, false, "Use only the first UTF8 step of the given string" " when computing log probabilities.") | |
| double_VAR_H (certainty_scale, 20.0, "Certainty scaling factor") | |
| double_VAR_H (stopper_nondict_certainty_base, -2.50, "Certainty threshold for non-dict words") | |
| double_VAR_H (stopper_phase2_certainty_rejection_offset, 1.0, "Reject certainty offset") | |
| INT_VAR_H (stopper_smallword_size, 2, "Size of dict word to be treated as non-dict word") | |
| double_VAR_H (stopper_certainty_per_char, -0.50, "Certainty to add for each dict char above small word size.") | |
| double_VAR_H (stopper_allowable_character_badness, 3.0, "Max certaintly variation allowed in a word (in sigma)") | |
| INT_VAR_H (stopper_debug_level, 0, "Stopper debug level") | |
| BOOL_VAR_H (stopper_no_acceptable_choices, false, "Make AcceptableChoice() always return false. Useful" " when there is a need to explore all segmentations") | |
| INT_VAR_H (tessedit_truncate_wordchoice_log, 10, "Max words to keep in list") | |
| STRING_VAR_H (word_to_debug, "", "Word for which stopper debug information" " should be printed to stdout") | |
| STRING_VAR_H (word_to_debug_lengths, "", "Lengths of unichars in word_to_debug") | |
| INT_VAR_H (fragments_debug, 0, "Debug character fragments") | |
| BOOL_VAR_H (segment_nonalphabetic_script, false, "Don't use any alphabetic-specific tricks." "Set to true in the traineddata config file for" " scripts that are cursive or inherently fixed-pitch") | |
| BOOL_VAR_H (save_doc_words, 0, "Save Document Words") | |
| double_VAR_H (doc_dict_pending_threshold, 0.0, "Worst certainty for using pending dictionary") | |
| double_VAR_H (doc_dict_certainty_threshold, -2.25, "Worst certainty" " for words that can be inserted into the document dictionary") | |
| INT_VAR_H (max_permuter_attempts, 10000, "Maximum number of different" " character choices to consider during permutation." " This limit is especially useful when user patterns" " are specified, since overly generic patterns can result in" " dawg search exploring an overly large number of options.") | |
go_deeper_dawg_fxn | |
If the choice being composed so far could be a dictionary word keep exploring choices. | |
| WERD_CHOICE * | dawg_permute_and_select (const BLOB_CHOICE_LIST_VECTOR &char_choices, float rating_limit) |
| void | go_deeper_dawg_fxn (const char *debug, const BLOB_CHOICE_LIST_VECTOR &char_choices, int char_choice_index, const CHAR_FRAGMENT_INFO *prev_char_frag_info, bool word_ending, WERD_CHOICE *word, float certainties[], float *limit, WERD_CHOICE *best_choice, int *attempts_left, void *void_more_args) |
| void | permute_choices (const char *debug, const BLOB_CHOICE_LIST_VECTOR &char_choices, int char_choice_index, const CHAR_FRAGMENT_INFO *prev_char_frag_info, WERD_CHOICE *word, float certainties[], float *limit, WERD_CHOICE *best_choice, int *attempts_left, void *more_args) |
| void | append_choices (const char *debug, const BLOB_CHOICE_LIST_VECTOR &char_choices, const BLOB_CHOICE &blob_choice, int char_choice_index, const CHAR_FRAGMENT_INFO *prev_char_frag_info, WERD_CHOICE *word, float certainties[], float *limit, WERD_CHOICE *best_choice, int *attempts_left, void *more_args) |
fragment_state | |
Given the current char choice and information about previously seen fragments, determines whether adjacent character fragments are present and whether they can be concatenated. The given prev_char_frag_info contains:
The output char_frag_info is filled in as follows:
| |
| bool | fragment_state_okay (UNICHAR_ID curr_unichar_id, float curr_rating, float curr_certainty, const CHAR_FRAGMENT_INFO *prev_char_frag_info, const char *debug, int word_ending, CHAR_FRAGMENT_INFO *char_frag_info) |
Static Public Member Functions | |
| static DawgCache * | GlobalDawgCache () |
| static NODE_REF | GetStartingNode (const Dawg *dawg, EDGE_REF edge_ref) |
| Returns the appropriate next node given the EDGE_REF. More... | |
| static bool | valid_word_permuter (uint8_t perm, bool numbers_ok) |
| Check all the DAWGs to see if this word is in any of them. More... | |
Public Attributes | |
| void(Dict::* | go_deeper_fxn_ )(const char *debug, const BLOB_CHOICE_LIST_VECTOR &char_choices, int char_choice_index, const CHAR_FRAGMENT_INFO *prev_char_frag_info, bool word_ending, WERD_CHOICE *word, float certainties[], float *limit, WERD_CHOICE *best_choice, int *attempts_left, void *void_more_args) |
| Pointer to go_deeper function. More... | |
| int(Dict::* | letter_is_okay_ )(void *void_dawg_args, const UNICHARSET &unicharset, UNICHAR_ID unichar_id, bool word_end) const |
| double(Dict::* | probability_in_context_ )(const char *lang, const char *context, int context_bytes, const char *character, int character_bytes) |
| Probability in context function used by the ngram permuter. More... | |
| float(Dict::* | params_model_classify_ )(const char *lang, void *path) |
Private Attributes | |
| CCUtil * | ccutil_ |
| UnicharAmbigs * | dang_ambigs_table_ |
| UnicharAmbigs * | replace_ambigs_table_ |
| float | reject_offset_ |
| UNICHAR_ID | wildcard_unichar_id_ |
| UNICHAR_ID | apostrophe_unichar_id_ |
| UNICHAR_ID | question_unichar_id_ |
| UNICHAR_ID | slash_unichar_id_ |
| UNICHAR_ID | hyphen_unichar_id_ |
| WERD_CHOICE * | hyphen_word_ |
| DawgPositionVector | hyphen_active_dawgs_ |
| bool | last_word_on_line_ |
| GenericVector< GenericVectorEqEq< UNICHAR_ID > > | equivalent_symbols_ |
| DawgCache * | dawg_cache_ |
| bool | dawg_cache_is_ours_ |
| DawgVector | dawgs_ |
| SuccessorListsVector | successors_ |
| Trie * | pending_words_ |
| Dawg * | bigram_dawg_ |
| Dawg * | freq_dawg_ |
| Dawg * | unambig_dawg_ |
| Dawg * | punc_dawg_ |
| Trie * | document_words_ |
| float | wordseg_rating_adjust_factor_ |
| FILE * | output_ambig_words_file_ |
| tesseract::Dict::Dict | ( | CCUtil * | image_ptr | ) |
| tesseract::Dict::~Dict | ( | ) |
| bool tesseract::Dict::absolute_garbage | ( | const WERD_CHOICE & | word, |
| const UNICHARSET & | unicharset | ||
| ) |
Returns true if the word looks like an absolute garbage (e.g. image mistakenly recognized as text).
| bool tesseract::Dict::AcceptableChoice | ( | const WERD_CHOICE & | best_choice, |
| XHeightConsistencyEnum | xheight_consistency | ||
| ) |
Returns true if the given best_choice is good enough to stop.
| bool tesseract::Dict::AcceptableResult | ( | WERD_RES * | word | ) | const |
Returns false if the best choice for the current word is questionable and should be tried again on the second pass or should be flagged to the user.
| void tesseract::Dict::add_document_word | ( | const WERD_CHOICE & | best_choice | ) |
Adds a word found on this document to the document specific dictionary.
| void tesseract::Dict::adjust_word | ( | WERD_CHOICE * | word, |
| bool | nonword, | ||
| XHeightConsistencyEnum | xheight_consistency, | ||
| float | additional_adjust, | ||
| bool | modify_rating, | ||
| bool | debug | ||
| ) |
Adjusts the rating of the given word.
| void tesseract::Dict::append_choices | ( | const char * | debug, |
| const BLOB_CHOICE_LIST_VECTOR & | char_choices, | ||
| const BLOB_CHOICE & | blob_choice, | ||
| int | char_choice_index, | ||
| const CHAR_FRAGMENT_INFO * | prev_char_frag_info, | ||
| WERD_CHOICE * | word, | ||
| float | certainties[], | ||
| float * | limit, | ||
| WERD_CHOICE * | best_choice, | ||
| int * | attempts_left, | ||
| void * | more_args | ||
| ) |
append_choices
Checks to see whether or not the next choice is worth appending to the word being generated. If so then keeps going deeper into the word.
This function assumes that Dict::go_deeper_fxn_ is set.
| tesseract::Dict::BOOL_VAR_H | ( | load_system_dawg | , |
| true | , | ||
| "Load system word dawg." | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | load_freq_dawg | , |
| true | , | ||
| "Load frequent word dawg." | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | load_unambig_dawg | , |
| true | , | ||
| "Load unambiguous word dawg." | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | load_punc_dawg | , |
| true | , | ||
| "Load dawg with punctuation patterns." | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | load_number_dawg | , |
| true | , | ||
| "Load dawg with number patterns." | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | load_bigram_dawg | , |
| true | , | ||
| "Load dawg with special word bigrams." | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | use_only_first_uft8_step | , |
| false | , | ||
| "Use only the first UTF8 step of the given string" " when computing log probabilities." | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | stopper_no_acceptable_choices | , |
| false | , | ||
| "Make AcceptableChoice() always return false. Useful" " when there is a need to explore all segmentations" | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | segment_nonalphabetic_script | , |
| false | , | ||
| "Don't use any alphabetic-specific tricks." "Set to true in the traineddata config file for" " scripts that are cursive or inherently fixed-pitch" | |||
| ) |
| tesseract::Dict::BOOL_VAR_H | ( | save_doc_words | , |
| 0 | , | ||
| "Save Document Words" | |||
| ) |
|
inline |
| int tesseract::Dict::case_ok | ( | const WERD_CHOICE & | word, |
| const UNICHARSET & | unicharset | ||
| ) | const |
Check a string to see if it matches a set of lexical rules.
|
inline |
|
inline |
|
inline |
If this word is hyphenated copy the base word (the part on the line before) of a hyphenated word into the given word. This function assumes that word is not nullptr.
| WERD_CHOICE * tesseract::Dict::dawg_permute_and_select | ( | const BLOB_CHOICE_LIST_VECTOR & | char_choices, |
| float | rating_limit | ||
| ) |
Recursively explore all the possible character combinations in the given char_choices. Use go_deeper_dawg_fxn() to explore all the dawgs in the dawgs_ vector in parallel and discard invalid words.
Allocate and return a WERD_CHOICE with the best valid word found.
dawg_permute_and_select
Recursively explore all the possible character combinations in the given char_choices. Use go_deeper_dawg_fxn() to search all the dawgs in the dawgs_ vector in parallel and discard invalid words.
Allocate and return a WERD_CHOICE with the best valid word found.
| void tesseract::Dict::DebugWordChoices | ( | ) |
Prints the current choices for this word to stdout.
| int tesseract::Dict::def_letter_is_okay | ( | void * | void_dawg_args, |
| const UNICHARSET & | unicharset, | ||
| UNICHAR_ID | unichar_id, | ||
| bool | word_end | ||
| ) | const |
Returns the maximal permuter code (from ccstruct/ratngs.h) if in light of the current state the letter at word_index in the given word is allowed according to at least one of the dawgs in dawgs_, otherwise returns NO_PERM.
The state is described by void_dawg_args, which are interpreted as DawgArgs and contain relevant active dawg positions. Each entry in the active_dawgs vector contains an index into the dawgs_ vector and an EDGE_REF that indicates the last edge followed in the dawg. It also may contain a position in the punctuation dawg which describes surrounding punctuation (see struct DawgPosition).
Input: At word_index 0 dawg_args->active_dawgs should contain an entry for each dawg that may start at the beginning of a word, with punc_ref and edge_ref initialized to NO_EDGE. Since the punctuation dawg includes the empty pattern " " (meaning anything without surrounding punctuation), having a single entry for the punctuation dawg will cover all dawgs reachable therefrom – that includes all number and word dawgs. The only dawg non-reachable from the punctuation_dawg is the pattern dawg. If hyphen state needs to be applied, initial dawg_args->active_dawgs can be copied from the saved hyphen state (maintained by Dict). For word_index > 0 the corresponding state (active_dawgs and punc position) can be obtained from dawg_args->updated_dawgs passed to def_letter_is_okay for word_index-1. Note: the function assumes that active_dawgs, and updated_dawgs member variables of dawg_args are not nullptr.
Output: The function fills in dawg_args->updated_dawgs vector with the entries for dawgs that contain the word up to the letter at word_index.
|
inline |
Default (no-op) implementation of probability in context function.
| void tesseract::Dict::default_dawgs | ( | DawgPositionVector * | anylength_dawgs, |
| bool | suppress_patterns | ||
| ) | const |
| tesseract::Dict::double_VAR_H | ( | xheight_penalty_subscripts | , |
| 0. | 125, | ||
| "Score penalty (0.1 = 10%) added if there are subscripts " "or superscripts in a | word, | ||
| but it is otherwise OK." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | xheight_penalty_inconsistent | , |
| 0. | 25, | ||
| "Score penalty (0.1 = 10%) added if an xheight is " "inconsistent." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | segment_penalty_dict_frequent_word | , |
| 1. | 0, | ||
| "Score multiplier for word matches which have good case and" "are frequent in the given language (lower is better)." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | segment_penalty_dict_case_ok | , |
| 1. | 1, | ||
| "Score multiplier for word matches that have good case " "(lower is better)." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | segment_penalty_dict_case_bad | , |
| 1. | 3125, | ||
| "Default score multiplier for word | matches, | ||
| which may have " "case issues(lower is better)." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | segment_penalty_dict_nonword | , |
| 1. | 25, | ||
| "Score multiplier for glyph fragment segmentations which " "do not match a dictionary word (lower is better)." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | segment_penalty_garbage | , |
| 1. | 50, | ||
| "Score multiplier for poorly cased strings that are not in" " the dictionary and generally look like garbage (lower is" " better)." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | certainty_scale | , |
| 20. | 0, | ||
| "Certainty scaling factor" | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | stopper_nondict_certainty_base | , |
| -2. | 50, | ||
| "Certainty threshold for non-dict words" | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | stopper_phase2_certainty_rejection_offset | , |
| 1. | 0, | ||
| "Reject certainty offset" | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | stopper_certainty_per_char | , |
| -0. | 50, | ||
| "Certainty to add for each dict char above small word size." | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | stopper_allowable_character_badness | , |
| 3. | 0, | ||
| "Max certaintly variation allowed in a word (in sigma)" | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | doc_dict_pending_threshold | , |
| 0. | 0, | ||
| "Worst certainty for using pending dictionary" | |||
| ) |
| tesseract::Dict::double_VAR_H | ( | doc_dict_certainty_threshold | , |
| -2. | 25, | ||
| "Worst certainty" " for words that can be inserted into the document dictionary" | |||
| ) |
| void tesseract::Dict::End | ( | ) |
| void tesseract::Dict::EndDangerousAmbigs | ( | ) |
| bool tesseract::Dict::FinishLoad | ( | ) |
| bool tesseract::Dict::fragment_state_okay | ( | UNICHAR_ID | curr_unichar_id, |
| float | curr_rating, | ||
| float | curr_certainty, | ||
| const CHAR_FRAGMENT_INFO * | prev_char_frag_info, | ||
| const char * | debug, | ||
| int | word_ending, | ||
| CHAR_FRAGMENT_INFO * | char_frag_info | ||
| ) |
|
inline |
|
inline |
|
inline |
Return i-th dawg pointer recorded in the dawgs_ vector.
|
inline |
Return the points to the punctuation dawg.
|
inlinestatic |
Returns the appropriate next node given the EDGE_REF.
|
inline |
Return the points to the unambiguous words dawg.
|
inline |
|
inline |
|
inline |
|
static |
Initialize Dict class - load dawgs from [lang].traineddata and user-specified wordlist and parttern list.
| void tesseract::Dict::go_deeper_dawg_fxn | ( | const char * | debug, |
| const BLOB_CHOICE_LIST_VECTOR & | char_choices, | ||
| int | char_choice_index, | ||
| const CHAR_FRAGMENT_INFO * | prev_char_frag_info, | ||
| bool | word_ending, | ||
| WERD_CHOICE * | word, | ||
| float | certainties[], | ||
| float * | limit, | ||
| WERD_CHOICE * | best_choice, | ||
| int * | attempts_left, | ||
| void * | void_more_args | ||
| ) |
If the choice being composed so far could be a dictionary word and we have not reached the end of the word keep exploring the char_choices further.
| int tesseract::Dict::good_choice | ( | const WERD_CHOICE & | choice | ) |
Returns true if a good answer is found for the unknown blob rating.
|
inline |
Check whether the word has a hyphen at the end.
|
inline |
Same as above, but check the unichar at the end of the word.
|
inline |
Size of the base word (the part on the line before) of a hyphenated word.
|
inline |
Returns true if we've recorded the beginning of a hyphenated word.
| void tesseract::Dict::init_active_dawgs | ( | DawgPositionVector * | active_dawgs, |
| bool | ambigs_mode | ||
| ) | const |
Fill the given active_dawgs vector with dawgs that could contain the beginning of the word. If hyphenated() returns true, copy the entries from hyphen_active_dawgs_ instead.
| tesseract::Dict::INT_VAR_H | ( | dawg_debug_level | , |
| 0 | , | ||
| "Set to 1 for general debug info" " | , | ||
| to 2 for more | details, | ||
| to 3 to see all the debug messages" | |||
| ) |
| tesseract::Dict::INT_VAR_H | ( | hyphen_debug_level | , |
| 0 | , | ||
| "Debug level for hyphenated words." | |||
| ) |
| tesseract::Dict::INT_VAR_H | ( | max_viterbi_list_size | , |
| 10 | , | ||
| "Maximum size of viterbi list." | |||
| ) |
| tesseract::Dict::INT_VAR_H | ( | stopper_smallword_size | , |
| 2 | , | ||
| "Size of dict word to be treated as non-dict word" | |||
| ) |
| tesseract::Dict::INT_VAR_H | ( | stopper_debug_level | , |
| 0 | , | ||
| "Stopper debug level" | |||
| ) |
| tesseract::Dict::INT_VAR_H | ( | tessedit_truncate_wordchoice_log | , |
| 10 | , | ||
| "Max words to keep in list" | |||
| ) |
| tesseract::Dict::INT_VAR_H | ( | fragments_debug | , |
| 0 | , | ||
| "Debug character fragments" | |||
| ) |
| tesseract::Dict::INT_VAR_H | ( | max_permuter_attempts | , |
| 10000 | , | ||
| "Maximum number of different" " character choices to consider during permutation." " This limit is especially useful when user patterns" " are | specified, | ||
| since overly generic patterns can result in" " dawg search exploring an overly large number of options." | |||
| ) |
|
inline |
| bool tesseract::Dict::IsSpaceDelimitedLang | ( | ) | const |
Returns true if the language is space-delimited (not CJ, or T).
| int tesseract::Dict::LengthOfShortestAlphaRun | ( | const WERD_CHOICE & | WordChoice | ) | const |
Returns the length of the shortest alpha run in WordChoice.
|
inline |
Calls letter_is_okay_ member function.
| void tesseract::Dict::Load | ( | const STRING & | lang, |
| TessdataManager * | data_file | ||
| ) |
| void tesseract::Dict::LoadLSTM | ( | const STRING & | lang, |
| TessdataManager * | data_file | ||
| ) |
| double tesseract::Dict::ngram_probability_in_context | ( | const char * | lang, |
| const char * | context, | ||
| int | context_bytes, | ||
| const char * | character, | ||
| int | character_bytes | ||
| ) |
| bool tesseract::Dict::NoDangerousAmbig | ( | WERD_CHOICE * | BestChoice, |
| DANGERR * | fixpt, | ||
| bool | fix_replaceable, | ||
| MATRIX * | ratings | ||
| ) |
|
inline |
Return the number of dawgs in the dawgs_ vector.
| float tesseract::Dict::ParamsModelClassify | ( | const char * | lang, |
| void * | path | ||
| ) |
| void tesseract::Dict::permute_choices | ( | const char * | debug, |
| const BLOB_CHOICE_LIST_VECTOR & | char_choices, | ||
| int | char_choice_index, | ||
| const CHAR_FRAGMENT_INFO * | prev_char_frag_info, | ||
| WERD_CHOICE * | word, | ||
| float | certainties[], | ||
| float * | limit, | ||
| WERD_CHOICE * | best_choice, | ||
| int * | attempts_left, | ||
| void * | more_args | ||
| ) |
permute_choices
Call append_choices() for each BLOB_CHOICE in BLOB_CHOICE_LIST with the given char_choice_index in char_choices.
|
inline |
Calls probability_in_context_ member function.
| void tesseract::Dict::ProcessPatternEdges | ( | const Dawg * | dawg, |
| const DawgPosition & | info, | ||
| UNICHAR_ID | unichar_id, | ||
| bool | word_end, | ||
| DawgArgs * | dawg_args, | ||
| PermuterType * | current_permuter | ||
| ) | const |
For each of the character classes of the given unichar_id (and the unichar_id itself) finds the corresponding outgoing node or self-loop in the given dawg and (after checking that it is valid) records it in dawg_args->updated_ative_dawgs. Updates current_permuter if any valid edges were found.
| void tesseract::Dict::ReplaceAmbig | ( | int | wrong_ngram_begin_index, |
| int | wrong_ngram_size, | ||
| UNICHAR_ID | correct_ngram_id, | ||
| WERD_CHOICE * | werd_choice, | ||
| MATRIX * | ratings | ||
| ) |
| void tesseract::Dict::reset_hyphen_vars | ( | bool | last_word_on_line | ) |
Unless the previous word was the last one on the line, and the current one is not (thus it is the first one on the line), erase hyphen_word_, clear hyphen_active_dawgs_, update last_word_on_line_.
|
inline |
| void tesseract::Dict::set_hyphen_word | ( | const WERD_CHOICE & | word, |
| const DawgPositionVector & | active_dawgs | ||
| ) |
Update hyphen_word_, and copy the given DawgPositionVectors into hyphen_active_dawgs_ .
| void tesseract::Dict::SettupStopperPass1 | ( | ) |
Sets up stopper variables in preparation for the first pass.
| void tesseract::Dict::SettupStopperPass2 | ( | ) |
Sets up stopper variables in preparation for the second pass.
| void tesseract::Dict::SetupForLoad | ( | DawgCache * | dawg_cache | ) |
|
inline |
|
inline |
Set wordseg_rating_adjust_factor_ to the given value.
| tesseract::Dict::STRING_VAR_H | ( | user_words_file | , |
| "" | , | ||
| "A filename of user-provided words." | |||
| ) |
Variable members. These have to be declared and initialized after image_ptr_, which contains the pointer to the params vector - the member of its base CCUtil class.
| tesseract::Dict::STRING_VAR_H | ( | user_words_suffix | , |
| "" | , | ||
| "A suffix of user-provided words located in tessdata." | |||
| ) |
| tesseract::Dict::STRING_VAR_H | ( | user_patterns_file | , |
| "" | , | ||
| "A filename of user-provided patterns." | |||
| ) |
| tesseract::Dict::STRING_VAR_H | ( | user_patterns_suffix | , |
| "" | , | ||
| "A suffix of user-provided patterns located in tessdata." | |||
| ) |
| tesseract::Dict::STRING_VAR_H | ( | output_ambig_words_file | , |
| "" | , | ||
| "Output file for ambiguities found in the dictionary" | |||
| ) |
| tesseract::Dict::STRING_VAR_H | ( | word_to_debug | , |
| "" | , | ||
| "Word for which stopper debug information" " should be printed to stdout" | |||
| ) |
| tesseract::Dict::STRING_VAR_H | ( | word_to_debug_lengths | , |
| "" | , | ||
| "Lengths of unichars in word_to_debug" | |||
| ) |
| int tesseract::Dict::UniformCertainties | ( | const WERD_CHOICE & | word | ) |
Returns true if the certainty of the BestChoice word is within a reasonable range of the average certainties for the best choices for each character in the segmentation. This test is used to catch words in which one character is much worse than the other characters in the word (i.e. false will be returned in that case). The algorithm computes the mean and std deviation of the certainties in the word with the worst certainty thrown out.
|
inline |
Copies word into best_choice if its rating is smaller than that of best_choice.
| bool tesseract::Dict::valid_bigram | ( | const WERD_CHOICE & | word1, |
| const WERD_CHOICE & | word2 | ||
| ) | const |
| bool tesseract::Dict::valid_punctuation | ( | const WERD_CHOICE & | word | ) |
Returns true if the word contains a valid punctuation pattern. Note: Since the domains of punctuation symbols and symblos used in numbers are not disjoint, a valid number might contain an invalid punctuation pattern (e.g. .99).
| int tesseract::Dict::valid_word | ( | const WERD_CHOICE & | word, |
| bool | numbers_ok | ||
| ) | const |
|
inline |
|
inline |
This function is used by api/tesseract_cube_combiner.cpp.
|
inline |
|
inlinestatic |
Check all the DAWGs to see if this word is in any of them.
Read/Write/Access special purpose dawgs which contain words only of a certain length (used for phrase search for non-space-delimited languages).
|
inline |
|
private |
|
private |
The following pointers are only cached for convenience. The dawgs will be deleted when dawgs_ vector is destroyed.
|
private |
Private member variables.
|
private |
Table that stores ambiguities computed during training (loaded when NoDangerousAmbigs() is called for the first time). Each entry i in the table stores a set of amibiguities whose wrong ngram starts with unichar id i.
|
private |
|
private |
|
private |
|
private |
|
private |
|
private |
| void(Dict::* tesseract::Dict::go_deeper_fxn_) (const char *debug, const BLOB_CHOICE_LIST_VECTOR &char_choices, int char_choice_index, const CHAR_FRAGMENT_INFO *prev_char_frag_info, bool word_ending, WERD_CHOICE *word, float certainties[], float *limit, WERD_CHOICE *best_choice, int *attempts_left, void *void_more_args) |
Pointer to go_deeper function.
|
private |
|
private |
|
private |
|
private |
| int(Dict::* tesseract::Dict::letter_is_okay_) (void *void_dawg_args, const UNICHARSET &unicharset, UNICHAR_ID unichar_id, bool word_end) const |
|
private |
| float(Dict::* tesseract::Dict::params_model_classify_) (const char *lang, void *path) |
|
private |
| double(Dict::* tesseract::Dict::probability_in_context_) (const char *lang, const char *context, int context_bytes, const char *character, int character_bytes) |
Probability in context function used by the ngram permuter.
|
private |
|
private |
|
private |
Additional certainty padding allowed before a word is rejected.
|
private |
Same as above, but for ambiguities with replace flag set.
|
private |
|
private |
|
private |
|
private |
|
private |
Current segmentation cost adjust factor for word rating. See comments in incorporate_segcost.
 1.8.13
1.8.13