|
Darknet/YOLO v6.0-57-gda64b9bc
Object Detection Framework
|

|
|
Darknet/YOLO v6.0-57-gda64b9bc
Object Detection Framework
|
|
Functions | |
| void | backward_shortcut_layer (Darknet::Layer &l, Darknet::NetworkState state) |
| void | backward_shortcut_layer_gpu (Darknet::Layer &l, Darknet::NetworkState state) |
| void | forward_shortcut_layer (Darknet::Layer &l, Darknet::NetworkState state) |
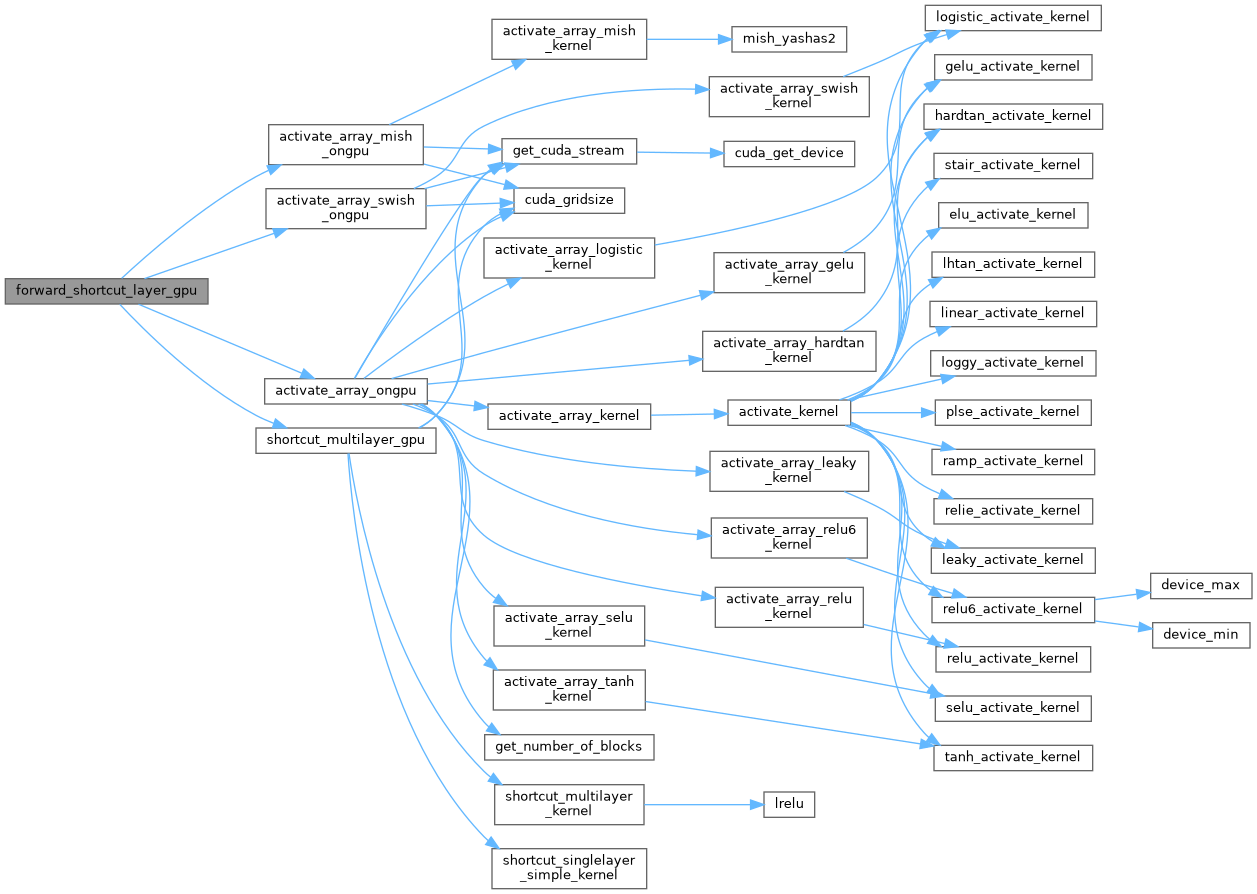
| void | forward_shortcut_layer_gpu (Darknet::Layer &l, Darknet::NetworkState state) |
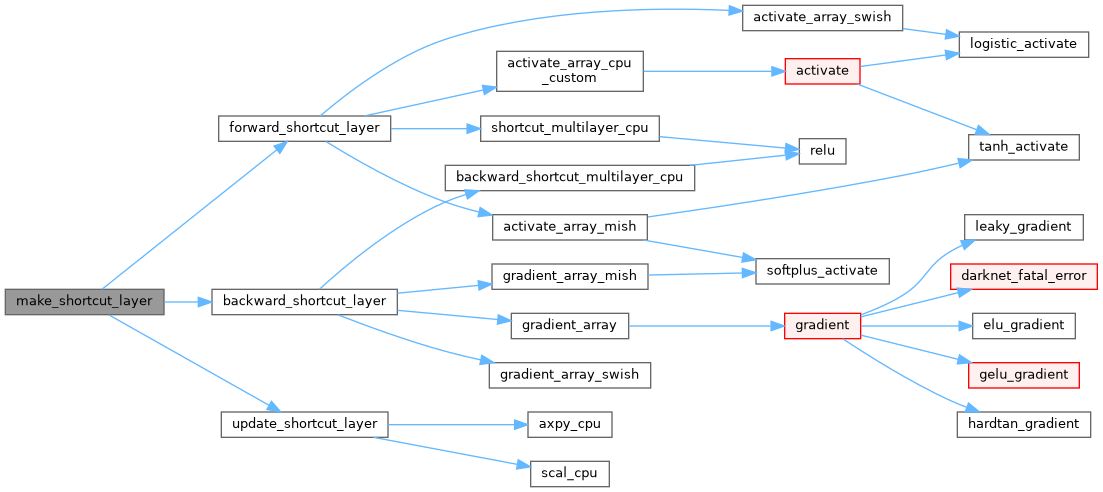
| Darknet::Layer | make_shortcut_layer (int batch, int n, int *input_layers, int *input_sizes, int w, int h, int c, float **layers_output, float **layers_delta, float **layers_output_gpu, float **layers_delta_gpu, WEIGHTS_TYPE_T weights_type, WEIGHTS_NORMALIZATION_T weights_normalization, ACTIVATION activation, int train) |
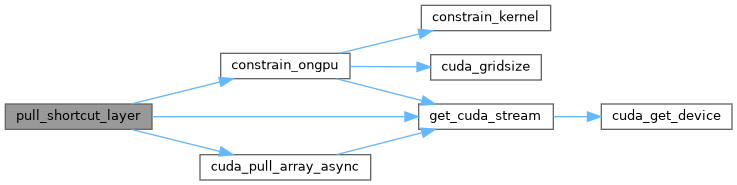
| void | pull_shortcut_layer (Darknet::Layer &l) |
| void | push_shortcut_layer (Darknet::Layer &l) |
| void | resize_shortcut_layer (Darknet::Layer *l, int w, int h, Darknet::Network *net) |
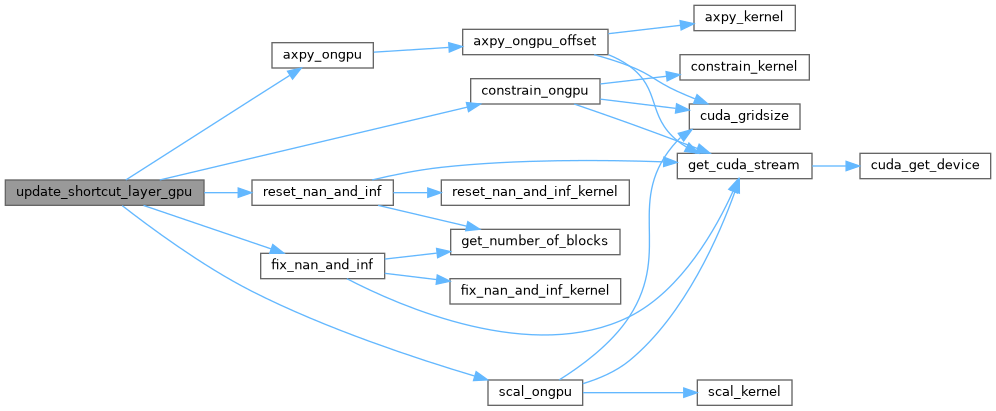
| void | update_shortcut_layer (Darknet::Layer &l, int batch, float learning_rate_init, float momentum, float decay) |
| void | update_shortcut_layer_gpu (Darknet::Layer &l, int batch, float learning_rate_init, float momentum, float decay, float loss_scale) |
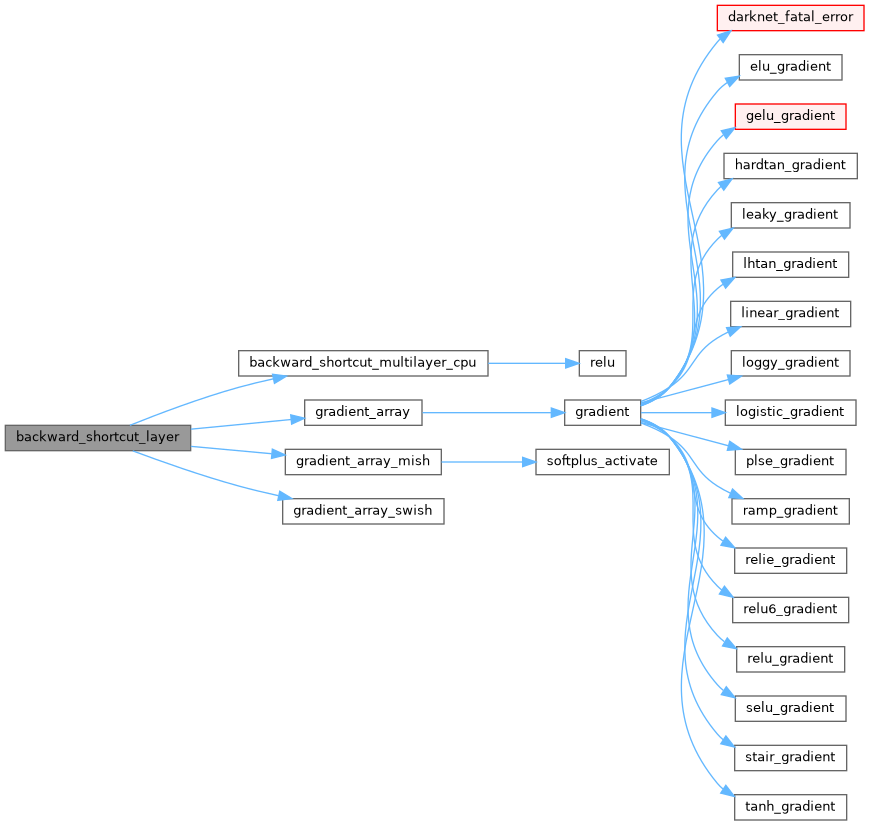
| void backward_shortcut_layer | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |

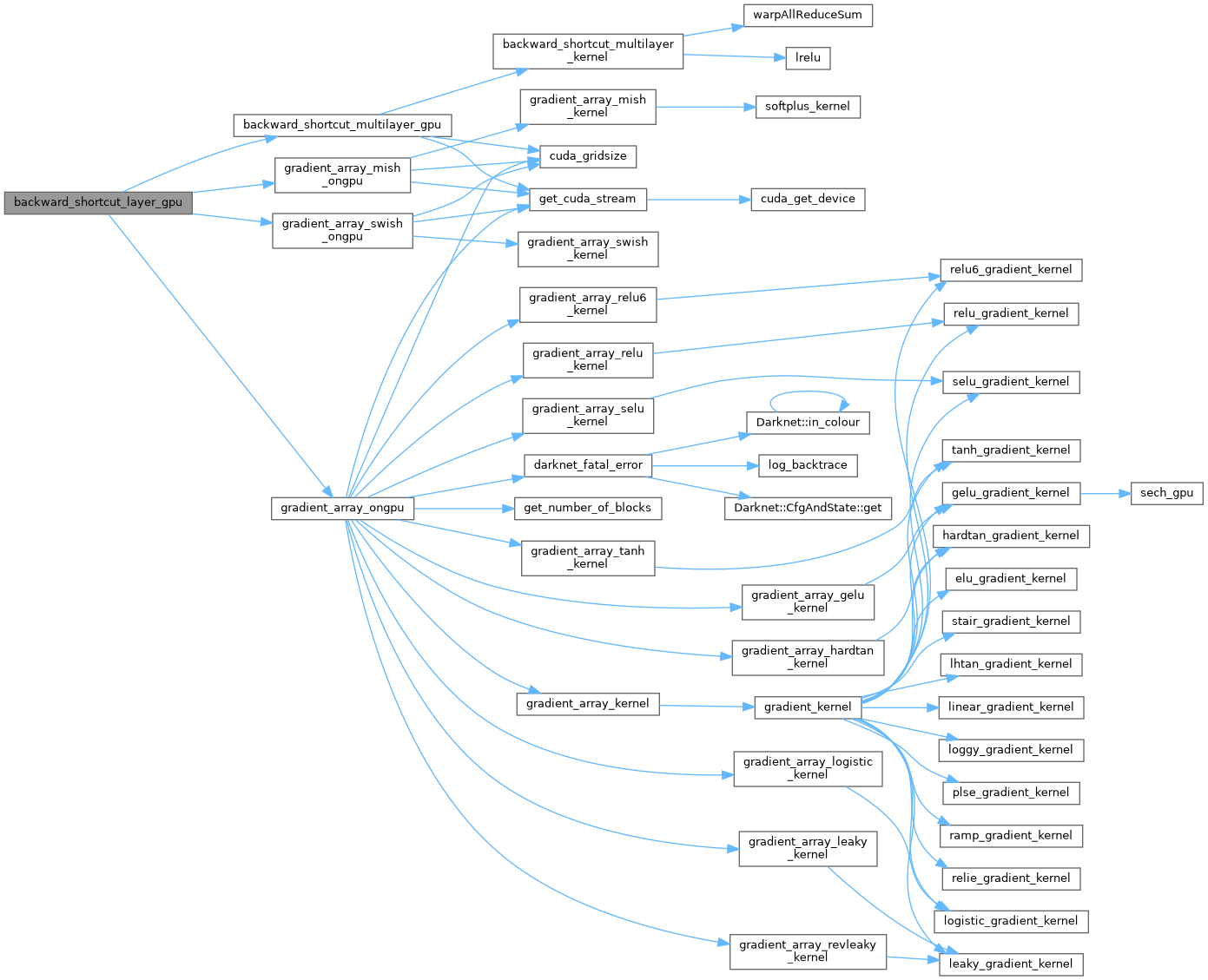
| void backward_shortcut_layer_gpu | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |

| void forward_shortcut_layer | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |
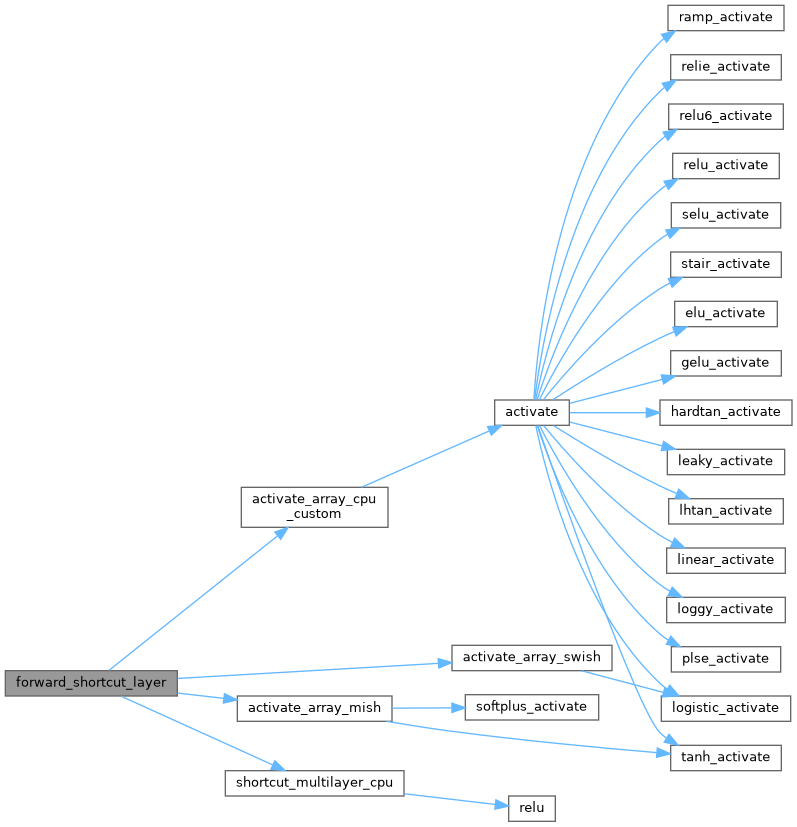

| void forward_shortcut_layer_gpu | ( | Darknet::Layer & | l, |
| Darknet::NetworkState | state | ||
| ) |

| Darknet::Layer make_shortcut_layer | ( | int | batch, |
| int | n, | ||
| int * | input_layers, | ||
| int * | input_sizes, | ||
| int | w, | ||
| int | h, | ||
| int | c, | ||
| float ** | layers_output, | ||
| float ** | layers_delta, | ||
| float ** | layers_output_gpu, | ||
| float ** | layers_delta_gpu, | ||
| WEIGHTS_TYPE_T | weights_type, | ||
| WEIGHTS_NORMALIZATION_T | weights_normalization, | ||
| ACTIVATION | activation, | ||
| int | train | ||
| ) |

| void pull_shortcut_layer | ( | Darknet::Layer & | l | ) |
| void push_shortcut_layer | ( | Darknet::Layer & | l | ) |

| void resize_shortcut_layer | ( | Darknet::Layer * | l, |
| int | w, | ||
| int | h, | ||
| Darknet::Network * | net | ||
| ) |


| void update_shortcut_layer | ( | Darknet::Layer & | l, |
| int | batch, | ||
| float | learning_rate_init, | ||
| float | momentum, | ||
| float | decay | ||
| ) |

| void update_shortcut_layer_gpu | ( | Darknet::Layer & | l, |
| int | batch, | ||
| float | learning_rate_init, | ||
| float | momentum, | ||
| float | decay, | ||
| float | loss_scale | ||
| ) |